구글이 사실 2015년부터 AI 칩을 만들고 있었다는 사실, 알고 계셨나요? 🤫 그동안 시장은 엔비디아(GPU)만 바라봤지만, 최근 공개된 7세대 TPU ‘아이언우드’가 판을 흔들고 있습니다.💡 핵심 요약 1️⃣ 압도적 가성비: 제미나이 3.0 학습의 주역! GPU 대비 비용 효율이 1.5~3배 높고 전력 소모는 50%나 줄였습니다. 2️⃣ 시장 충격: 메타(Meta)가 데이터센터에 TPU 도입을 검토한다는 소식에 엔비디아 주가가 출렁였죠. 3️⃣…
1. Google TPU의 개요 및 역사적 맥락
1.1. TPU의 등장과 초기 시장 인식
Google의 TPU(Tensor Processing Unit)는 AI 전용 칩(ASIC)으로, 2016년 Google I/O에서 공식 발표되었으나, 실제로는 2015년부터 이미 구글 데이터센터 내부에서 랭크브레인(RankBrain), 알파고(AlphaGo), 번역 등 대부분의 머신러닝 워크로드에 대량 배포되어 사용 중이었습니다.
• TPU 타임라인: v1 (2016) → v2 (2017) → v3 (2018, 성능 8배↑) → v4 (2020~2021년경).
• 2016년 ~ 2019년 TPU에 대한 시장 인식과 실제 상황 요약
| 구분 | TPU의 실제 존재 및 사용 현황 | 시장의 인식 및 주목도 |
| TPU 타임라인 | TPU v1은 2016년 5월 Google I/O에서 공식 발표되었으며, 실제로는 2015년부터 구글 데이터센터 내부에서 이미 사용되고 있었습니다. 구글은 당시 랭크브레인, 알파고, 번역, 사진 등 대부분의 머신러닝 워크로드를 이미 TPU로 구동하고 있었다고 공식적으로 밝혔습니다. | **GPU(엔비디아)와 FPGA(인텔/자일링스)**만이 당시 반도체 호황기(AI 반도체 슈퍼사이클 초기)의 주요 AI 칩으로 여겨졌습니다. |
| 시장 인식의 괴리 | TPU v2는 2017년 5월에 발표되었고, Cloud TPU 서비스로 외부에 공개된 것은 2018년부터였습니다. | 투자자들과 시장은 TPU를 **“구글 내부에서만 쓰는 블랙박스 칩”**으로 인식하여 외부에서는 크게 주목받지 못했습니다. |
| 외부 사용 시점 | 일반 기업이 Cloud TPU를 실제로 사용하기 시작한 것은 2019년에서 2020년 이후였습니다. | 2016년에서 2019년 구간에 TPU가 시장의 주요 투자 대상에서 제외된 이유는, 당시 시장이 인지하고 투자했던 범용 AI 칩은 GPU(엔비디아)가 거의 전부였기 때문입니다. |
• 결론: Google의 TPU는 2016년부터 실제 대량 배포되어 구글의 AI 경쟁력 핵심이었지만, 외부 공개 및 범용성이 낮았기 때문에 시장은 이를 간과했습니다. 시장은 2022년 ChatGPT 사태가 터지고 나서야 “구글이 이미 AI 칩을 8년째 만들고 있었다”는 사실을 깨달은 셈입니다.
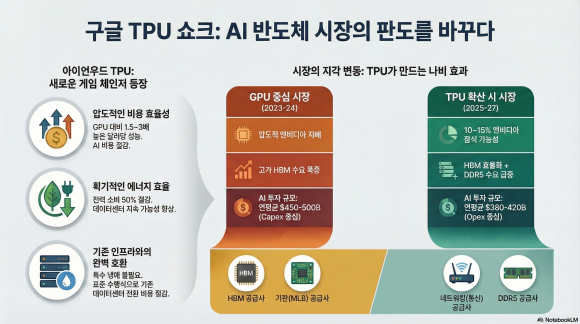
1.2. Ironwood TPU (7세대)의 등장과 파장
2022년 이후 ChatGPT 등장과 함께, 구글이 8년째 AI 칩을 만들고 있었다는 사실이 시장에 알려지면서 TPU에 대한 인식이 바뀌었습니다. 어제(2025년 11월 25일) 발표된 **Ironwood TPU (7세대)**는 Gemini 3.0 모델의 성능 향상과 맞물려 폭발적인 반응을 일으켰습니다. 특히 Meta가 2027년 데이터센터에 TPU를 수십억 달러 규모로 도입 검토 중이라는 소식과 함께 Nvidia 주가가 4-6% 급락하며 시장에 엄청난 반향을 일으켰습니다.
| 특징 | 설명 | Gemini 3.0과의 연계 |
| 컴퓨팅 파워 | 포드당 42.5 엑사플롭스(ExaFLOPS) – 9,000개 이상 칩 구성. 이전 세대(v5p) 대비 4배 스케일업. | Gemini 3.0이 전체 TPU로만 트레이닝된 첫 프론티어 모델. Nvidia GPU 없이도 글로벌 스케일 트레이닝 가능. |
| 비용 효율성 | GPU 대비 1.5~3배 높은 성능/달러 비율. 인퍼런스 비용 50%↓ (구글 내부 추정). | Gemini 3.0의 토큰당 비용 대폭 절감. 구글이 가격 전쟁에서 우위 확보 가능. |
| 에너지 효율 | 전력 소비 50%↓ (최신 세대 적용). 지속 가능성 강조. | SparseCores 2세대 덕분에 멀티모달 워크로드(이미지/비디오 처리) 임베딩 작업 2.3배 빨라짐. |
| 스케일링 & 네트워킹 | AI Hypercomputer와 통합, 40% 네트워크 성능 향상 (지연 거의 0). 클라우드 외부 확장 (Meta 등). | Gemini 3.0을 Vertex AI, Google Search 등 전 제품군에 즉시 배포. Anthropic처럼 100만 개 TPU 계약으로 외부 고객 확대. |
| 한계 | 특정 AI 프레임워크(TensorFlow/JAX)에 최적화 – 범용성 낮음 (Nvidia의 CUDA만큼 유연하지 않음). | 클라우드 워크로드는 여전히 Nvidia GPU 병행 (구글 자체 인정). |
——————————————————————————–
2. TPU점유율 확대에 따른 반도체 시장 및 공급망 영향 분석
2.1. HBM 의존성 변화 및 DRAM 시장 영향
Ironwood TPU는 HBM(High Bandwidth Memory) 의존성을 줄이는 방향을 제시합니다. TPU는 HBM을 사용하지만, 효율적 설계 덕분에 GPU처럼 대량의 HBM 스택을 쌓지 않고도 고성능을 달성하며, HBM을 더 효율적으로 사용합니다.
| 영향 영역 | 세부 설명 | 시장 함의 (2025~2027 전망) |
| Nvidia GPU 시장 점유율 하락 | Ironwood가 B200과 비슷한 성능으로 1.5~3배 비용 효율 제공. Meta/Anthropic 등 고객 이탈 우려. | Nvidia 매출 10~15% 잠식 가능. 주가 변동성 ↑ (이미 11월 Nvidia -4.7%). |
| HBM 수요 변화 & 공급 안정화 | TPU가 HBM3E 192GB 사용하지만, 효율적 설계(SparseCore)로 단위 칩당 HBM 소비 30%↓. | HBM 시장 성장(70%) 지속되지만, GPU만큼 폭발적이지 않음. HBM 가격 안정화로 전체 AI 칩 비용 20% ↓. |
| DDR5/LPDDR5 수요 증가 | TPU가 추론(Inference) 워크로드에서 HBM 대신 LPDDR5X나 DDR5를 대체 캐시로 활용하여 수요를 증가시킴. | DDR5 RDIMM 가격 2배 ↑, LPDDR5X 시장 CAGR 11.7%. 삼성전자(DRAM 70% 일반 DRAM) 같은 다각화 업체 수혜 ↑. |
| 에너지/지속 가능성 혁신 | TPU 첫 세대 대비 30배 효율, 전력 소비 50% 절감. HBM 병목 대신 ICI(Inter-Chip Interconnect) 네트워킹 강조. | 반도체 에너지 소비 줄여 규제 완화. AMD/Intel 등 경쟁사 ASIC 개발 촉진. |
| 생태계 재편 | Nvidia 중심의 “범용 GPU → 맞춤형 ASIC(TPU 등)”으로 재편 전망. | ASIC 비중 20% ↑ (GPU 60% → 50%). AWS(Trainium)/MS(Azure Maia) 등 Hyperscaler 맞춤 칩 확산. |
2.2. TPU 밸류체인: 기판(MLB) vs. 네트워킹(통신)
TPU의 대규모 클러스터링(수십만 칩 연결)에서 **네트워킹(통신)**이 전략적 핵심으로 부상하지만, 기판(MLB) 공급사도 단기 실적 측면에서 큰 수혜를 봅니다.
| 영역 | 기판 (MLB)의 역할 & 중요성 | 네트워킹 (통신)의 역할 & 중요성 |
| 기본 기능 | TPU 칩을 지지하는 고밀도 다층 PCB(인쇄회로 기판). 다중적층 MLB 적용 시 신호 무결성↑, 열 관리↑. | ICI(Inter-Chip Interconnect, 칩 간 고속 연결 9.6 Tb/s) 및 DCN(Data Center Network)을 통한 팟(Pod) 간 연결. |
| 비교: 왜 네트워킹이 더 중요한가? | 기판은 ‘단일 칩 안정성’에 초점 (TPU 100만 개 출하 시 1,000억 원 매출 기여). | 네트워킹은 ‘전체 시스템 스케일링’에 필수 – TPU 팟이 400,000 칩 클러스터로 확장될 때 병목을 풀어줌. |
| 시장 영향 | 밸류체인 하단: PCB 공급사 수혜 (이수페타시스 등). TPU 공급 확대(2배)로 ISU Petasys 영업이익 14% 상향. | 밸류체인 상단: 네트워크 장비사 (Broadcom, Cisco) 수혜. TPU가 Nvidia를 위협하려면 통신 혁신(OCS 등)이 핵심 무기. |
| 브로드컴 주가 상승 이유 | TPU ICI(9.6 Tb/s) 및 Jupiter 네트워크 칩셋 공급. 구글 자체 설계(in-house)이나, Broadcom이 설계 최적화 및 제조 지원의 핵심 파트너 역할. | 네트워킹 중요도 증가 + TPU 설계 협력 효과가 주가 상승의 주요 동력. |
2.3. 기판 업체 (수혜 vs. 피해) 및 수요처 변화
기판 시장은 ‘누가 물량을 많이 찍어내느냐'(발주처)에 따라 수혜지가 재편되는 구조입니다. TPU 중심으로 물량이 이동하면서 업체별 희비가 엇갈립니다.
| 회사 | 주요 수요처 | TPU 수혜 이유 | Nvidia 의존도 & 리스크 |
| 이수페타시스 (수혜) | 구글(TPU 40-50% 점유), MS·Intel, Nvidia(서버 보드). | TPU 7세대 MLB 공급 확대(연초 계획 2배↑). 차세대 학습용 TPU 다중적층 MLB 적용으로 ASP 구조적 상승. | 중간 – TPU 성장으로 상쇄. TPU 물량 성장이 GPU(2030%)보다 23배 높음. |
| 삼성전기 (수혜) | 빅테크 4개(구글·AMD 등 GPU/ASIC), 인텔·퀄컴. | FC-BGA 기판 ‘완판 체제'(2027년까지). TPU/GPU 모두 커버하는 다각화 강점. | 높음 – 하지만 TPU 다각화로 완충. 가장 안정적인 포지션. |
| 심텍 (피해주 → 기회) | Nvidia(GB200 패키징·소캠 협력), 삼성·모바일. | TPU 공급 미미 – ASIC 전환 시 대체 어려움. 하지만 2026년 Nvidia의 소캠(SoCAMM, 저전력 메모리 모듈) 양산 시작(초기 매출 900억~1천억 원 추정)으로 밸류에이션 할증 기대. | 높음 – TPU 잠식 시 매출 타격 가능. 소캠 성공 시 회복. |
| 두산 전자BG (수혜) | Nvidia, 구글, MS 등 빅테크. | AI 반도체 핵심 소재인 동박적층판(CCL)을 Nvidia GB200/GB300에 납품 시작. TPU 네트워킹 CCL 공급 가능성. | 강점 – Nvidia와 TPU 듀얼 수혜로 안정적. |
2.4. 냉각 방식과 전력 효율
TPU의 냉각 방식은 GPU 대비 기존 데이터센터(DC)에 설치하기 용이합니다.
| 측면 | TPU (Ironwood v7) | GPU (Blackwell B200) | 인사이트 (2025 트렌드) |
| 기본 방식 | 수랭식 표준 (표준 물, 특수 냉매 불필요). | 액랭 필수 (특수 냉매 가능). | TPU는 물 기반으로 전환 비용(20~30% ↓)이 저렴하고, 환경 우위 (탄소 40% ↓). |
| 공랭식 호환 | 제한적 (저밀도 추론 시 가능, 2배 성능 저하). | 제한적 (5~10kW 랙 한계). | TPU 효율 덕에 공랭 DC 호환성이 GPU보다 20% 유연. |
| 전력 수요 감소 | TPU 전환 시 동일 AI 수요 가정 하에 전체 전력 수요 20~40% 감소 가능. | GPU는 고밀도 열(150kW+/랙)로 업그레이드 강제. | TPU는 ‘지속 가능성’ 리더로, 기존 DC 재활용을 촉진하여 Capex 15~20%를 절감. |
——————————————————————————–
3. TPU 점유율 확대에 따른 거시 경제 및 투자 사이클 영향
3.1. AI 투자금액 및 GDP 영향 (Capex → Opex 전환)
TPU의 범용화와 비용 효율화는 빅테크의 AI Capex(자본 지출) 성장률을 둔화시키고 Opex(운영 지출, 전력·유지) 비중을 확대시키는 방향으로 작용합니다. 이는 전체 AI 투자금액 자체가 기존 예상보다 낮아질 수 있음을 의미합니다.
| 포인트 | GPU 중심 가정 (2023~2024) | TPU 확산 시나리오 (2025~2027) | 변화 요인 (기판 물량배분 + DRAM 믹스 변화) | 경제적 함의 & 비용 감소 이유 (왜 돈이 덜 드는가?) |
| HBM / 전력 수요 | HBM 70~100% YoY↑ 랙당 100~140 kW | HBM 40~50% YoY↑ 랙당 60~90 kW | HBM 비중 18% → 13~15% 전력 효율 2~4배 ↑ → 랙당 소비 30~40% ↓ | 동일 성능을 내기 위해 필요한 HBM 스택 수가 줄고, 전기·냉각 비용이 35~45% 감소 → 연간 Opex $300~400M/100k-칩 클러스터 절감 |
| 네트워킹 중요도 | NVLink + InfiniBand 중심 | ICI + Jupiter + OCS 광스위치 중심 | 네트워킹 기판·스위치 수요 40~60% ↑ (Broadcom·마벨 등) | 데이터 이동 에너지 50% ↓ + 광학 스위치 전환으로 전력·냉각 부하 감소 → 네트워킹 Opex 20~30% 절감 |
| DDR5 / LPDDR5 수요 | 서버 DDR5 30% 점유 | 서버 DDR5 55~60% LPDDR5X 급증 | DDR5 RDIMM 40% → 55~60% LPDDR5X 5% → 12~15% (추론용 오프로드 증가) | HBM(5~10배 가격) → DDR5(2~3배 가격) 대체로 메모리 구매 단가 40~60% ↓ → 100k-칩 클러스터당 메모리 비용 $1.2B → $0.7~0.8B |
| AI 투자금액 | 연평균 $450~500B | 연평균 $380~420B (15~20% ↓) | 동일 워크로드 기준 Capex·Opex 15~25% 절감 (전력·냉각·HBM 비용 ↓) | ① GPU 단가 30% ↓ ② 전력·냉각 35% ↓ ③ 메모리 믹스 비용 45% ↓ ④ 기존 DC 재활용 → 신규 DC 건설비 50% ↓ → 총 TCO 30~40% 감소 |
| 기판 물량 배분 | Nvidia 65~70% | Google TPU 40~45% + Nvidia 40~45% | 1위 이수페타시스 (TPU 40%+) 2 삼성전기 (TPU+GPU+AMD) 3 심텍 (소캠 회복 여부) | 기판 단가는 비슷하나, TPU 기판이 더 고밀도·고부가라 ASP 15~25% ↑ → 납품사 마진 ↑, 하지만 전체 기판 구매 금액은 10% 내외 감소 |
| TSMC 파운드리 | AI 매출 비중 45% | AI 매출 비중 55~60% | 누가 이겨도 TSMC 3nm·CoWoS 물량은 그대로 또는 소폭 증가 → 수혜 불변 | TPU 효율화로 웨이퍼당 성능이 올라가지만, 총 AI 칩 물량 자체는 유지 → TSMC 매출은 오히려 5~10% 증가 (단가 상승 효과) |
[단기 GDP 영향]
미국 경제에서 AI Capex(I, 투자)가 GDP 성장을 주도하는 상황에서, TPU 효율화로 I 증가율이 둔화되면, C/G/NX 둔화와 맞물려 단기적으로 GDP 성장률이 기존 예상 대비 0.2~0.5%p 낮아질 가능성이 존재합니다.
3.2. 증시 멀티플 및 DRAM 업계 리스크
기존 GPU 가격 상승 → 선제적 비용 집행 → 반도체 멀티플 확장의 메커니즘이 TPU 전환으로 약화되면, 반도체 업종 주가의 일부 되돌림(PER 압축 5~10%)을 초래할 수 있습니다.
• SK하이닉스/삼성전자: TPU 전환 시 HBM 효율화로 HBM 마진 프리미엄이 일부 약화될 수 있지만, TPU도 HBM을 사용하고 DDR5 믹스 개선으로 전체 실적은 지지됩니다.
• 마이크론 (MU)의 TPU 확산에 따른 리스크 및 전망 요약
마이크론(MU)은 TPU(Ironwood 7세대)의 확산과 그에 따른 HBM(High Bandwidth Memory) 시장의 효율화에 대해 다른 메모리 업체 대비 상대적으로 높은 리스크를 지니고 있지만, 최근의 HBM 기술력 강화로 인해 주가 측면에서는 긍정적인 모멘텀을 유지하고 있습니다.
1) TPU 확산에 따른 리스크 요인: HBM 마진 의존도
마이크론은 일반 DRAM 시장에서 삼성전자 및 SK하이닉스 대비 **비용 경쟁력과 생산 능력 면에서 열위(10~15% 생산성 열위)**를 보입니다. 따라서 전체 매출의 약 70%를 차지하는 일반 DRAM의 마진(현재 22.35%)이 약한 상황에서, **HBM 판매에 따른 높은 마진(70% 이상)**에 대한 의존도가 높습니다.
TPU가 GPU를 대체하며 효율화될 경우, HBM 소비가 20~30% 감소할 가능성이 있으며, 이로 인해 HBM 가격 프리미엄(현재 DDR5 대비 5~10배)이 3~5배 수준으로 압축될 수 있습니다. 이 시나리오대로 진행될 경우, 마이크론은 HBM 마진을 10~20% 반납해야 할 리스크가 있으며, 이는 다른 업체 대비 전체 수익성에 미치는 부정적 영향이 더 클 수 있습니다.
2) 리스크를 상쇄하는 완충 요인 및 주가 모멘텀
이러한 리스크에도 불구하고, 마이크론은 최근 강력한 기술적 모멘텀을 보이며 주가를 지지하고 있습니다.
• HBM3E 경쟁력 강화: 마이크론은 HBM3E 12-Hi 수율 개선을 통해 엔비디아(Nvidia) 및 AMD 공급을 확대하며 HBM 시장 점유율을 21%까지 끌어올려 삼성전자(17%)를 잠시 추월했습니다.
• HBM4 기대감: 2026년 HBM4 샘플 출시 및 양산이 기대되며, 이는 엔비디아의 차세대 칩(Rubin) 공급과 연계되어 향후 HBM 매출 $8B 이상을 목표로 하고 있습니다.
• DRAM 시장 전체 강세: TPU 전환으로 인해 일반 DRAM(DDR5/LPDDR5)의 수요가 증가하는 점이 마이크론의 일반 DRAM 열위 부분을 보완하며 전체 실적을 지지하고 있습니다.
• 주가 움직임: 최근 3거래일(2025년 11월 24일~26일) 동안 마이크론의 주가는 **양봉(상승세)**을 기록하며 회복력을 보여주었는데, 이는 HBM 마진 반납 우려에도 불구하고 AI 메모리 붐에 대한 시장의 기대가 반영된 결과입니다.
3) 정리
PU 확산은 마이크론에게 HBM 마진 반납 리스크를 안겨주지만, 최근 HBM3E/HBM4 기술 선점과 AI 메모리 시장의 총량적 성장 기대가 단기적으로 주가를 방어하고 있습니다.